Evaluation Download

Download a time-limited evaluation version of our SDKs.
High Performance OPC UA Client & Server SDK
This HP SDK makes OPC UA usable in smallest embedded devices and thus “IoT Ready”. The package contains client- and server-side SDK. Written in pure AnsiC (C99) code this SDK has highes flexibility when porting to other platforms.The single thread / single task architecture allows for running the SDK in parallel to real time task. The fully asynchrounous API can not block and guarantees continous communication without interference with main real time task of your device. Furthermore this highly optimized implementation guarantees improved performance for high end servers, which must be able to handle thousands of connections in parallel.
With a new software architecture and new implementation from scratch we have achieved all the goals to get OPC UA communication into the smallest IIoT devices. Of course, the new implementation is still wire-compatible with the original OPC Foundation Stacks.
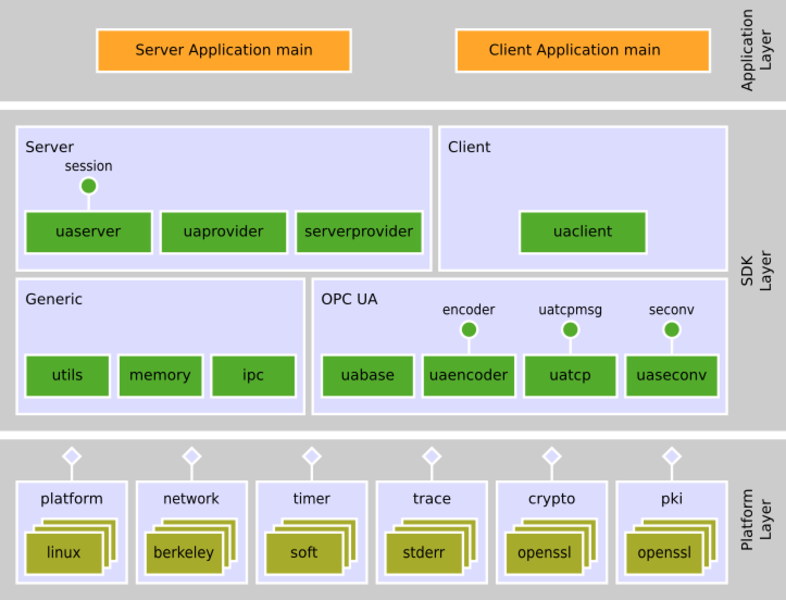
Parallelism Revisited
One problem of many network applications is bad multi-threaded design. Too many threads are created without a clear concept, which lead to enormous waste of resources, bad performance due to locking problems, and trashed CPU caches. Some implementations even create one thread per connection, which is the worst design in a sense of scalability.
With the new SDK, we have designed a set of OPC UA components which can work in parallel, independently of each other, and thus achieve superior performance on multi-core CPUs without interference. In addition, this architecture allows to drive the components from a single threaded main loop in smallest micro controllers.
Sandboxing
The component design allows to run components like the network encoder/decoder in a separate process. This not only can improve performance, it also allows to benefit from sandboxing mechanisms like Linux Secure Computing Mode. This allows to disable any operating system calls for this process. In the case of a bug which could lead to an exploit, the process is terminated by the OS as soon as an attacker tries to access a forbidden operating system function. The master process detects this and can restart the terminated process.
Asynchronous Network API
The new OPC UA implementation is based on a completely asynchronous network API as an OS abstraction layer. The different network backends allow to benefit from modern OS specific APIs like POSIX AIO, Linux epoll, BSD kqueue or Windows Completion Port APIs. These APIs don’t suffer from scalability problems like the ancient Berkeley Socket APIs and are the enabler for high performance server applications. The usage of these APIs allows to reduce the number of context switches and copy operations which improves the performance when scaling to thousands of connections.
With this new API we also have introduced solutions for non-blocking domain name resolution, which we have identified as a big design problem in today’s implementations.
Asynchronous Crypto and PKI APIs
As with network APIs, today’s crypto implementations suffer from synchronous blocking implementations. Our new OPC UA implementation is designed completely asynchronously to solve this issue. Two different backends are supported out of the box: OpenSSL and mbedTLS. More backends can be added over time. This concept also allows to add hardware accelerated cryptography. The asynchronous design now allows to delegate an encryption job to a hardware chip, continue OPC UA communications and later on process the result of the hardware encryption, even in a single-threaded environment.
Improved Performance
As one of the biggest performance bottle-necks we have identified the encoder/decoder component of today’s ANSI C based OPC UA implementation. Even though it is faster than Java and C# based stacks, the whole potential was not reached. With a complete redesign of the encoding procedure we could gain a performance boost by a factor of 10 for the encoding process. This can lead to an overall performance boost of the OPC UA protocol up to a factor of 4, depending on the type of data transferred.
Small Footprint
During the whole design process we kept a focus on small footprint to make the software usable for embedded devices. A modular concept, configurable memory pools, and efficient implementation make it perfectly suitable for smallest devices and for Internet of Things (IoT). On an ARM based demonstration device running Euros Real Time Operating system we were able to integrate an OPC UA server in 300K Codesize including the Operating System. A new table based address space concept allows to integrate huge address spaces with a fraction of the memory required in other SDKs. It also supports read only address space models that completely reside in ROM.
Software Quality
To ensure the best quality from the beginning, we developed a comprehensive test environment. Using this toolset, we are already able to achieve 98% line coverage and 95% branch coverage.
Supported OPC UA Services
- Discovery Service Set: FindServers, GetEndpoints
- Secure Channel Service Set: OpenSecureChannel, CloseSecureChannel
- Session Service Set: CreateSession, ActivateSession, CloseSession
- View Service Set: Browse, BrowseNext, TranslateBrowsePathToNodeIds, RegisterNodes, UnregisterNodes
- Attribute Service Set: Read, Write
- Method Service Set: Call
- MonitoredItem Service Set: CreateMonitoredItems, ModifyMonitoredItems, DeleteMonitoredItems, SetMonitoringMode
- Subscription Service Set: CreateSubscription, ModifySubscription, DeleteSubscription, SetPublishingMode, Publish, Republish
(All missing services are implementable on interface level, but contain no default implementation.)
Product Variants
| Editions | Source Code |
| License Types | Source Code Developer License (Single Seat), Evaluation License |
| Supported Compilers | GCC, Clang, MinGW, MSVC |
| Supported Platforms | Linux, Windows, vxWorks, QNX, Segger embOS, _custom_ |
| Supported Architectures | x86, x86_64, ARM (32bit and 64bit, both little and big endian) |
| Supported Crypto Libraries | OpenSSL v1.1.x, OpenSSL v3.x, mbedTLS >= v2.23 |
| Development | CMake |
Read the complete software license agreement.
Supported Features and Profiles
- Data Access
- Events Access
- Alarm & Condition
- Historical Access
- Methods
- Security, Authentication
- UA-TCP, UA-SecureConversation, UA-Binary
- UA Role Permission Support
More detailed information can be found on the next tab.
| General | Nano Embedded Device 2017 Server Profile, Micro Embedded Device 2017 Server Profile, Embedded 2017 UA Server Profile |
| Generic | Core Server Facat, Exposes Type System Server Facet, Base Server Facet, Method Server Facet, File Access Server Facet, NodeManagement Server Facet |
| Security Profiles | None, Basic128Rsa15(default-off), Basic256(default-off), Basic256Sha256, Aes128-Sha256-RsaOaep, Aes256-Sha256-RsaPss |
| User Tokens | Anonymous, User Name Password, User X509 |
| Data Access | DataAccess Server Facet, ComplexType 2017 Server Facet |
| Historical Access | All services and datatypes are provided on interface level to implement this. There is no further SDK support like e.g. Database integration. A history example server is included in the tutorials of the SDK documentation. |
| Events | Address Space Notifier Server Facet, Standard Event Subscription Server Facet |
| Methods | Method Server Facet |
| Alarms & Conditions | A&C Base Condition Server Facet, A&C Refresh2 Server Facet, A&C Address Space Instance Server Facet, A&C Enable Server Facet, A&C Acknowledgeable Alarm Server Facet, A&C Alarm Server Facet |
| GDS Support | The server and clients side can be managed by a Global Discovery Server. |
- C99 as minimum compiler requirement (also supports MSVC with C98 + extensions)
- Configurable Memory Pools
- Single-threaded asynchronous architecture (no locking, no race conditions)
- UA Binary File format for loading information models. Can contain additional information like e.g. runtime address for underlying systems.
- Loading information models to Flash (ROM) to minimize RAM requirements
- UaModeler support to generate complete server applications.
- Capability to create self-signed certificates on startup
- UA Certificate Management Utility uacertmgr
- Built-in user management and account management tool uapasswd
- IPv6 Support
- Asynchronous domain name resolution (non-blocking)
- IPC Framework
- Multiprocess Mode with Sandboxing (Linux only) possible using IPC Framework
- Statemachine Framework for easy implementation of asynchronous logic
- Easy portability through backend concept: Platform layer, crypto, pki, network and trace use a defined interface with configurable backends. New custom backends can be added when porting to a new target.
- Unittest framework included
- Unit test suite included for testing ports to new targets
- In-depth documentation with examples and tutorials is included.
- OPC UA Server SDK including Clientside
- Information model XML file to binary file converter
- Information model XML file to C code converter
- IPC framework
- Unit test framework
- Unit test suite to support porting the SDK
- CMake build files
- API documentation, examples and tutorials
- 15 support incidents
- first year maintenance
- one UaModeler runtime license
UaGateway
The UaGateway is designed to integrate “classic” OPC products into OPC UA Environments. Its main features are connecting UA clients to COM/DCOM Servers (Wrapper), accessing UA Servers with COM/DCOM clients (Proxy), and tunneling COM/DCOM through a secure UA connection. Please refer to the UaGateway product page for further information.
OPC UA Training
Unified Automation offers seminars, workshop, and hands-on classes to help you getting started with OPC UA and our SDK Products. Please refer to the following pages for more information.
It is also possible to book in-house training tailored to your company’s reqirements.
OPC UA Book
 The book “OPC Unified Architecture” is written by Wolfgang Mahnke, Stefan-Helmut Leitner, and Matthias Damm, one of the trainers of Unified Automation.
The book “OPC Unified Architecture” is written by Wolfgang Mahnke, Stefan-Helmut Leitner, and Matthias Damm, one of the trainers of Unified Automation.
“This book provides you a solid foundation to learn everything you could ever want to know about developing world-class products for multi-vendor interoperability based on OPC UA”, says Tom Burke, President of the OPC Foundation